Heap space use on load docx
Hi
We are usind docx4j for replacing variable replacement in docx files. Until now has worked fine in production for several months. But today we hit this error:
java.lang.OutOfMemoryError: Java heap space
at java.util.Arrays.copyOf(Arrays.java:3236)
at java.io.ByteArrayOutputStream.grow(ByteArrayOutputStream.java:118)
at java.io.ByteArrayOutputStream.ensureCapacity(ByteArrayOutputStream.java:93)
at java.io.ByteArrayOutputStream.write(ByteArrayOutputStream.java:153)
at java.io.BufferedOutputStream.flushBuffer(BufferedOutputStream.java:82)
at java.io.BufferedOutputStream.write(BufferedOutputStream.java:95)
at org.docx4j.openpackaging.io3.stores.ZipPartStore.getBytesFromInputStream(ZipPartStore.java:191)
at org.docx4j.openpackaging.io3.stores.ZipPartStore.<init>(ZipPartStore.java:154)
at org.docx4j.openpackaging.packages.OpcPackage.load(OpcPackage.java:559)
at org.docx4j.openpackaging.packages.OpcPackage.load(OpcPackage.java:410)
at org.docx4j.openpackaging.packages.OpcPackage.load(OpcPackage.java:376)
at org.docx4j.openpackaging.packages.OpcPackage.load(OpcPackage.java:341)
at org.docx4j.openpackaging.packages.WordprocessingMLPackage.load(WordprocessingMLPackage.java:180)
The file is a 4.0MB word with several images. When loading it the Heap of the JVM sky rockets from 100Mb to more than 300Mb. 200MB heap for loading a 4Mb file?
Getting the heap from my local machine:
Heap Before loading file
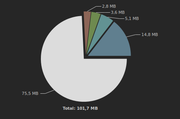
Heap after loading
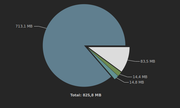
Thats 700Mb of byte[] created when loading a 4Mb file!!
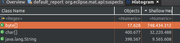

The calling code. We arenusing Spring Resource class. Files are red from a remote server, so they are not local files.:
There is clearly something odd here. Any hints? I will be debbing the load code to try to figure out what may be happening.
Edit1:
I downloaded docx4j code. This is log of a simple Junit that runs my code with mockito.
Heap size before MB: 238
01-12-2020 18:19:52.684 DEBUG o.g.documents.DocumentServiceImpl.replaceVars - replaceVars(Resource word=null, HashMap<String,String> mappings={fecha=null, secuencial=1}) - start
01-12-2020 18:19:52.684 DEBUG o.g.documents.DocumentServiceImpl.replaceVars - replaceVars(Resource word=null, HashMap<String,String> mappings={fecha=null, secuencial=1}) - start
01-12-2020 18:19:52.700 INFO o.d.o.io3.stores.ZipPartStore.<init> - Start reading zip...
01-12-2020 18:19:52.707 INFO o.d.o.io3.stores.ZipPartStore.<init> - Heap size before read MB: 238
01-12-2020 18:19:58.811 INFO o.d.o.io3.stores.ZipPartStore.<init> - Heap size after read MB: 726
Heap total after test MB: 3390
Changing /docx4j-core/src/main/java/org/docx4j/openpackaging/io3/stores/ZipPartStore.java getBytesFromInputStream to this code:
Size can be read from the entry.getSize().
Get some interesting result, but more testing is needed to ensure is not luck.
01-12-2020 20:14:33.849 INFO o.d.o.io3.stores.ZipPartStore.<init> - Heap size before read MB: 238
01-12-2020 20:14:33.849 INFO o.d.o.io3.stores.ZipPartStore.<init> - Heap size before read MB: 238
01-12-2020 20:14:34.608 INFO o.d.o.io3.stores.ZipPartStore.<init> - Heap size after read MB: 398
Will keep looking at this and update here with more info.
Best regards,
Guillermo
We are usind docx4j for replacing variable replacement in docx files. Until now has worked fine in production for several months. But today we hit this error:
java.lang.OutOfMemoryError: Java heap space
at java.util.Arrays.copyOf(Arrays.java:3236)
at java.io.ByteArrayOutputStream.grow(ByteArrayOutputStream.java:118)
at java.io.ByteArrayOutputStream.ensureCapacity(ByteArrayOutputStream.java:93)
at java.io.ByteArrayOutputStream.write(ByteArrayOutputStream.java:153)
at java.io.BufferedOutputStream.flushBuffer(BufferedOutputStream.java:82)
at java.io.BufferedOutputStream.write(BufferedOutputStream.java:95)
at org.docx4j.openpackaging.io3.stores.ZipPartStore.getBytesFromInputStream(ZipPartStore.java:191)
at org.docx4j.openpackaging.io3.stores.ZipPartStore.<init>(ZipPartStore.java:154)
at org.docx4j.openpackaging.packages.OpcPackage.load(OpcPackage.java:559)
at org.docx4j.openpackaging.packages.OpcPackage.load(OpcPackage.java:410)
at org.docx4j.openpackaging.packages.OpcPackage.load(OpcPackage.java:376)
at org.docx4j.openpackaging.packages.OpcPackage.load(OpcPackage.java:341)
at org.docx4j.openpackaging.packages.WordprocessingMLPackage.load(WordprocessingMLPackage.java:180)
The file is a 4.0MB word with several images. When loading it the Heap of the JVM sky rockets from 100Mb to more than 300Mb. 200MB heap for loading a 4Mb file?
Getting the heap from my local machine:
Heap Before loading file
Heap after loading
Thats 700Mb of byte[] created when loading a 4Mb file!!
The calling code. We arenusing Spring Resource class. Files are red from a remote server, so they are not local files.:
- Code: Select all
private byte[] replaceVars(Resource word, HashMap<String, String> mappings) {
if (logger.isDebugEnabled()) {
logger.debug("replaceVars(Resource word={}, HashMap<String,String> mappings={}) - start",
word.getFilename(), mappings);
}
ByteArrayOutputStream baos = new ByteArrayOutputStream();
InputStream is = null;
try {
is = word.getInputStream();
WordprocessingMLPackage wordMLPackage = WordprocessingMLPackage.load(is);
VariablePrepare.prepare(wordMLPackage);
wordMLPackage.getMainDocumentPart().variableReplace(mappings);
wordMLPackage.save(baos);
return baos.toByteArray();
} catch (Exception e) {
logger.error("replaceVars(Resource, HashMap<String,String>)", e);
} finally {
try {
is.close();
baos.close();
} catch (IOException e) {
logger.error("replaceVars(Resource, HashMap<String,String>)", e);
}
}
return null;
}
There is clearly something odd here. Any hints? I will be debbing the load code to try to figure out what may be happening.
Edit1:
I downloaded docx4j code. This is log of a simple Junit that runs my code with mockito.
Heap size before MB: 238
01-12-2020 18:19:52.684 DEBUG o.g.documents.DocumentServiceImpl.replaceVars - replaceVars(Resource word=null, HashMap<String,String> mappings={fecha=null, secuencial=1}) - start
01-12-2020 18:19:52.684 DEBUG o.g.documents.DocumentServiceImpl.replaceVars - replaceVars(Resource word=null, HashMap<String,String> mappings={fecha=null, secuencial=1}) - start
01-12-2020 18:19:52.700 INFO o.d.o.io3.stores.ZipPartStore.<init> - Start reading zip...
01-12-2020 18:19:52.707 INFO o.d.o.io3.stores.ZipPartStore.<init> - Heap size before read MB: 238
01-12-2020 18:19:58.811 INFO o.d.o.io3.stores.ZipPartStore.<init> - Heap size after read MB: 726
Heap total after test MB: 3390
Changing /docx4j-core/src/main/java/org/docx4j/openpackaging/io3/stores/ZipPartStore.java getBytesFromInputStream to this code:
Size can be read from the entry.getSize().
- Code: Select all
private byte[] getBytesFromInputStream(InputStream is, int size)
throws Exception {
if (size == -1) {
BufferedInputStream bufIn = new BufferedInputStream(is);
ByteArrayOutputStream baos = new ByteArrayOutputStream();
BufferedOutputStream bos = new BufferedOutputStream(baos);
int c = bufIn.read();
while (c != -1) {
bos.write(c);
c = bufIn.read();
}
bos.flush();
baos.flush();
//bufIn.close(); //don't do that, since it closes the ZipInputStream after we've read an entry!
bos.close();
return baos.toByteArray();
}else {
byte[] targetArray = new byte[size];
int read = is.read(targetArray);
int offset = read;
while (read != -1) {
read = is.read(targetArray,offset, size-offset);
offset += read;
}
return targetArray;
}
}
Get some interesting result, but more testing is needed to ensure is not luck.
01-12-2020 20:14:33.849 INFO o.d.o.io3.stores.ZipPartStore.<init> - Heap size before read MB: 238
01-12-2020 20:14:33.849 INFO o.d.o.io3.stores.ZipPartStore.<init> - Heap size before read MB: 238
01-12-2020 20:14:34.608 INFO o.d.o.io3.stores.ZipPartStore.<init> - Heap size after read MB: 398
Will keep looking at this and update here with more info.
Best regards,
Guillermo