Mar 12 2018
Scaling the PDF Converter with AWS Fargate
This is a walkthrough of deploying the PDF Converter on Amazon’s FarGate.
What is Fargate? New since November 2017, its an easy way of deploying containers on AWS ECS. You don’t have to manage the underlying EC2 instances, and the wizard takes care of the setup, so you can be up and running in less than 20 mins!
With FarGate, you make a “cluster” which you can easily size to suit a known conversion volume, or have it auto-scale with load. Largely thanks to Docker!
This walkthrough assumes you already have an AWS login.
To getting things working:
- there’s 4 steps in Amazon’s firstRun wizard: https://console.aws.amazon.com/ecs/home?region=us-east-1#/firstRun
- then you configure the health check path
But first, check things are configured correctly for ECS in your Amazon account. Since FarGate currently only works in N.Virginia, visit https://console.aws.amazon.com/ecs/home?region=us-east-1#/getStarted
ECS FirstRun Wizard
If you don’t already see the “Getting Started” wizard pictured below, click https://console.aws.amazon.com/ecs/home?region=us-east-1#/firstRun (this is easier than “create new cluster” at https://console.aws.amazon.com/ecs/home?region=us-east-1#/clusters/create/new since it also creates a Service and Task, but more importantly, your load balancer).
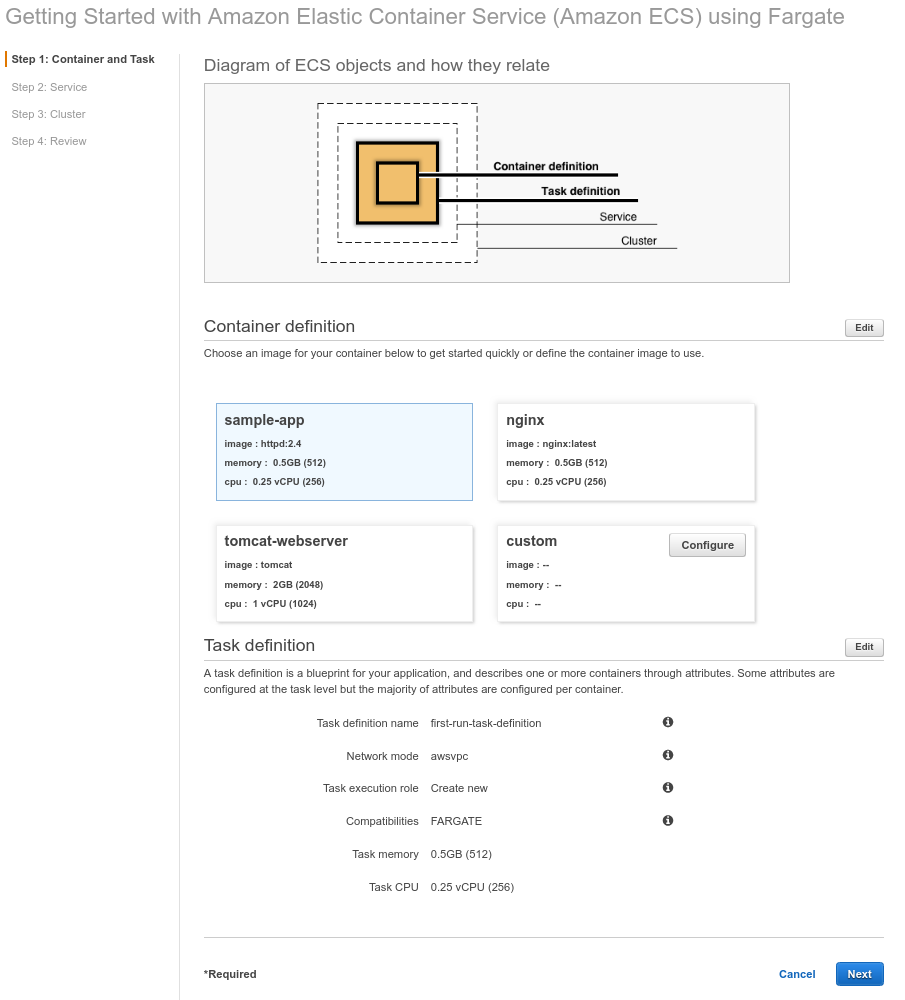
In the “Container definition” section, click the “configure” button on the “custom” image.
Type the following in image: plutext/plutext-document-services:2.1-0, and set the other values as per the image below:
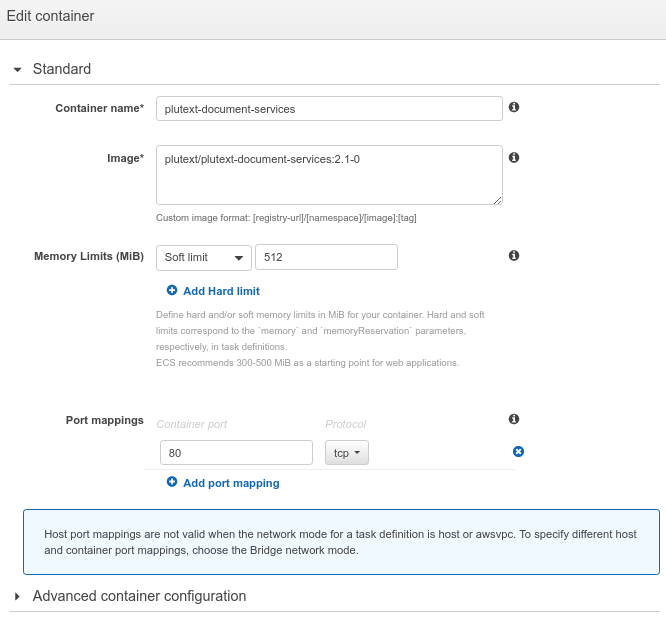
Next, in “Task definition”, edit the task definition name, to say: pds-task-definition
Click next.
Service
On the “service” screen, click “edit” to set the number of tasks to 2, and choose “Application Load Balancer”.
Click next.
Cluster
On this screen, just change the cluster name to: plutext-document-services
When you click next, the review screen should show:

Click “Create”. The wizard will perform various tasks; it might take 3 or 4 mins.
When it is done, you should see:
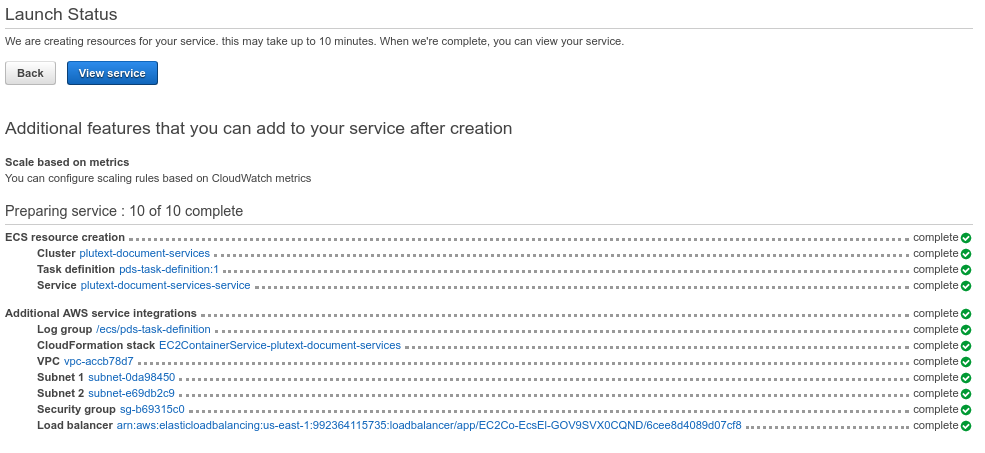
Click the “view service” button.
Health Check
You need to set the health check path in your load balancer. (Unfortunately, FarGate currently doesn’t populate this from the HEALTHCHECK statement in your Dockerfile)
So in your cluster, click your service, where you’ll see the load balancer target group:
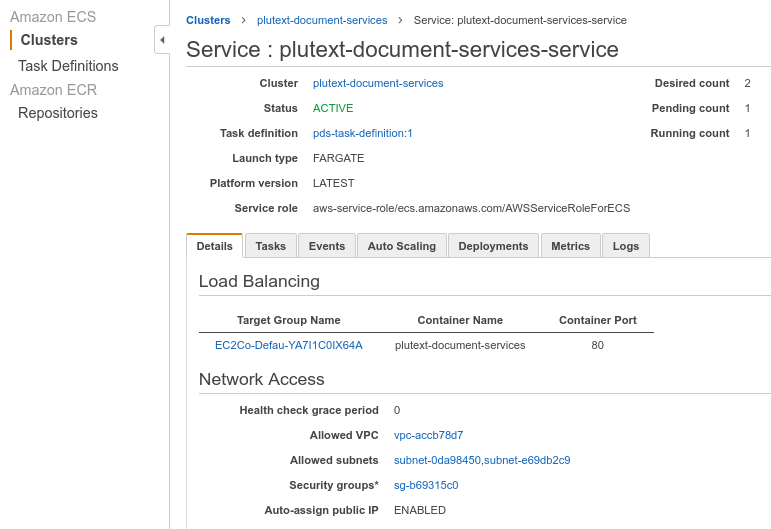
Click that.
Now, you’re in your load balancer, where you can click “edit health check” and enter path: /v1/00000000-0000-0000-0000-000000000000/ping
Result should be:
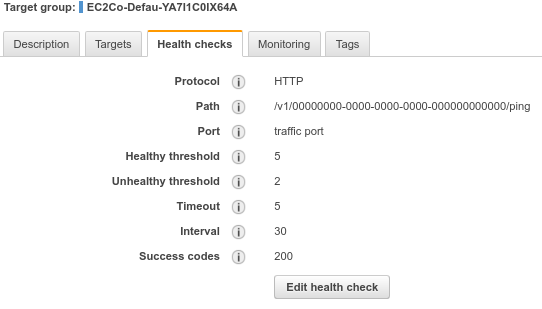
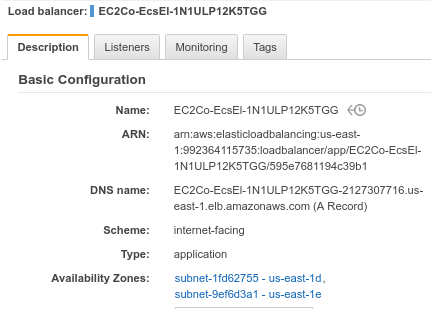
Before you go back to your service, click on the load balancer itself, and make a note of its DNS name. You’ll see the host name there in the basic configuration:
Now if you go back to your service, on the “tasks” tab, you should see:
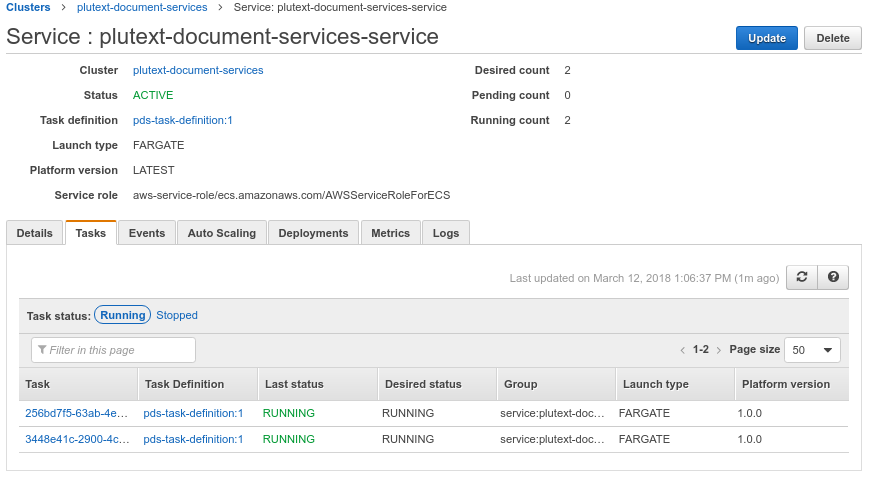
ie “RUNNING”
Try it out!
To convert a document, you need the DNS host name of the load balancer you made a note of above. Now you can test with something like:
curl -v -X POST –data-binary @HelloWorld.docx -o out.pdf http://EC2Co-EcsEl-1N1ULP12K5TGG-2127307716.us-east-1.elb.amazonaws.com:80/v1/00000000-0000-0000-0000-000000000000/convert
Check for “200 OK” and try opening out.pdf.
Next steps
In our next post, we’ll configure HTTPS, and in the one after that, we’ll add a license key.