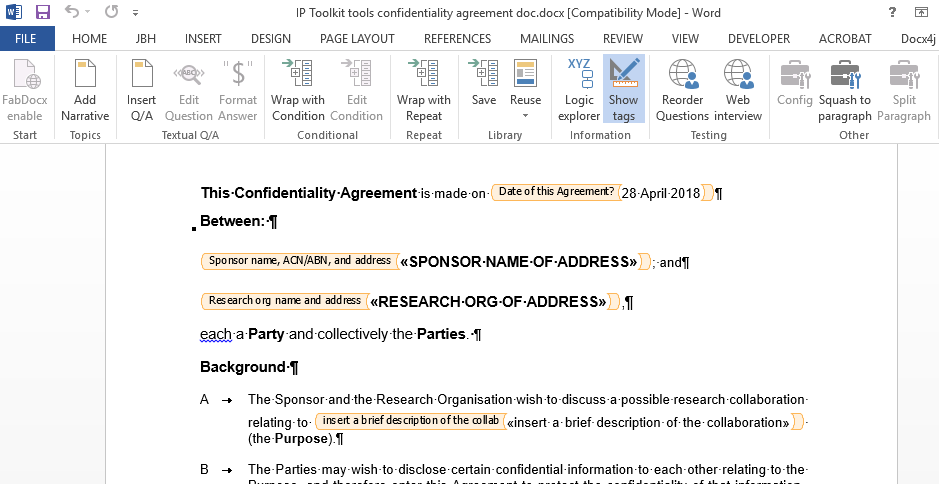
Sep 05 2020
Fast PDF templating using XSL FO
If your objective is to generate PDF documents only (ie you have no need for docx or HTML output), then you might consider an XSL FO templating approach.
That is, you do variable replacement in the XSL FO document.
This could be faster than generating a docx file first each time.
You could use any of the templating libraries for this. Google “java xml templating -sap -hana”
Using a templating library is probably better than working with a lower level Java XML API so you don’t reinvent the wheel.
For example, https://www.thymeleaf.org/ (especially if you are using Spring).
Below is a quick demo of using a template library called pebble to create an invoice:
<dependency>
<groupId>io.pebbletemplates</groupId>
<artifactId>pebble</artifactId>
<version>3.1.4</version>
</dependency>
This demo shows simple variable replacement, repeating content, and conditional content. Java and XSL FO template attached.
How do you get the XSL FO in the first place? You can create a docx document using Microsoft Word, then convert that to XSL FO using docx4j.
Then you add the templating commands to the XSL FO file using your favourite text editor.
Java code:
import java.io.IOException;
import java.io.StringWriter;
import java.io.Writer;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import com.mitchellbosecke.pebble.PebbleEngine;
import com.mitchellbosecke.pebble.template.PebbleTemplate;
public class PebbleFoTemplating {
public static void main(String[] args) throws IOException {
PebbleEngine engine = new PebbleEngine.Builder().build();
PebbleTemplate compiledTemplate = engine.getTemplate(System.getProperty("user.dir") + "/invoice_fo.xml");
Map<String, Object> context = new HashMap<>();
context.put("name", "Mitchell");
// repeat demo, see https://pebbletemplates.io/wiki/tag/for/
List<Fruit> repeat_fruit = new ArrayList<Fruit>();
repeat_fruit.add(new Fruit("apples", "$20"));
repeat_fruit.add(new Fruit("oranges", "$40"));
context.put("fruitList", repeat_fruit);
// condition, see https://pebbletemplates.io/wiki/tag/if/
context.put("condition1", Boolean.FALSE);
Writer writer = new StringWriter();
compiledTemplate.evaluate(writer, context);
String output = writer.toString();
System.out.println(output);
}
static class Fruit {
Fruit(String name, String price) {
this.name=name;
this.price=price;
}
public String name;
public String price;
}
}
Pebble XSL FO template:
<?xml version="1.0" encoding="utf-8"?>
<fo:root xmlns:fo="http://www.w3.org/1999/XSL/Format"
xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006">
<layout-master-set
xmlns="http://www.w3.org/1999/XSL/Format">
<simple-page-master margin-bottom="12mm"
margin-left="1in" margin-right="1in" margin-top="12mm"
master-name="s1-simple" page-height="297mm" page-width="210mm">
<region-body column-count="1" column-gap="12mm"
margin-bottom="36.0pt" margin-left="0mm" margin-right="0mm"
margin-top="36.0pt" />
<region-before extent="0.0pt"
region-name="xsl-region-before-simple" />
<region-after extent="0.0pt"
region-name="xsl-region-after-simple" />
</simple-page-master>
<page-sequence-master master-name="s1">
<repeatable-page-master-alternatives>
<conditional-page-master-reference
master-reference="s1-simple" />
</repeatable-page-master-alternatives>
</page-sequence-master>
</layout-master-set>
<fo:page-sequence force-page-count="no-force"
id="section_s1" format="" master-reference="s1">
<fo:flow flow-name="xsl-region-body">
<fo:block font-size="11.0pt" line-height="115%"
space-after="4mm" white-space-treatment="preserve">
</fo:block>
<fo:block font-size="11.0pt" line-height="115%"
space-after="4mm" text-align="center">
<inline xmlns="http://www.w3.org/1999/XSL/Format"
font-family="Calibri">INVOICE</inline>
</fo:block>
<fo:block font-size="11.0pt" line-height="115%"
space-after="4mm">
<inline xmlns="http://www.w3.org/1999/XSL/Format"
font-family="Calibri">{{ name }}</inline>
</fo:block>
<fo:block font-size="11.0pt" line-height="115%"
space-after="4mm" white-space-treatment="preserve">
</fo:block>
<fo:table border-bottom-color="#000000"
border-bottom-style="solid" border-bottom-width="0.5pt"
border-collapse="collapse" border-left-color="#000000"
border-left-style="solid" border-left-width="0.5pt"
border-right-color="#000000" border-right-style="solid"
border-right-width="0.5pt" border-top-color="#000000"
border-top-style="solid" border-top-width="0.5pt"
display-align="before" start-indent="0in" table-layout="fixed"
width="159mm">
<fo:table-column column-number="1"
column-width="119mm" />
<fo:table-column column-number="2"
column-width="1.58in" />
<fo:table-body start-indent="0in">
<fo:table-row>
<fo:table-cell border-bottom-color="#000000"
border-bottom-style="solid" border-bottom-width="0.5pt"
border-left-color="#000000" border-left-style="solid"
border-left-width="0.5pt" border-right-color="#000000"
border-right-style="solid" border-right-width="0.5pt"
border-top-color="#000000" border-top-style="solid"
border-top-width="0.5pt" padding-bottom="0mm"
padding-left="1.91mm" padding-right="1.91mm" padding-top="0mm">
<block xmlns="http://www.w3.org/1999/XSL/Format"
font-size="11.0pt" line-height="100%" space-after="0in">
<inline font-family="Calibri">Item</inline>
</block>
</fo:table-cell>
<fo:table-cell border-bottom-color="#000000"
border-bottom-style="solid" border-bottom-width="0.5pt"
border-left-color="#000000" border-left-style="solid"
border-left-width="0.5pt" border-right-color="#000000"
border-right-style="solid" border-right-width="0.5pt"
border-top-color="#000000" border-top-style="solid"
border-top-width="0.5pt" padding-bottom="0mm"
padding-left="1.91mm" padding-right="1.91mm" padding-top="0mm">
<block xmlns="http://www.w3.org/1999/XSL/Format"
font-size="11.0pt" line-height="100%" space-after="0in">
<inline font-family="Calibri">Price</inline>
</block>
</fo:table-cell>
</fo:table-row>
{% for fruit in fruitList %}
<fo:table-row>
<fo:table-cell border-bottom-color="#000000"
border-bottom-style="solid" border-bottom-width="0.5pt"
border-left-color="#000000" border-left-style="solid"
border-left-width="0.5pt" border-right-color="#000000"
border-right-style="solid" border-right-width="0.5pt"
border-top-color="#000000" border-top-style="solid"
border-top-width="0.5pt" padding-bottom="0mm"
padding-left="1.91mm" padding-right="1.91mm" padding-top="0mm">
<block xmlns="http://www.w3.org/1999/XSL/Format"
font-size="11.0pt" line-height="100%" space-after="0in">
<inline font-family="Calibri">{{ fruit.name }}</inline>
</block>
</fo:table-cell>
<fo:table-cell border-bottom-color="#000000"
border-bottom-style="solid" border-bottom-width="0.5pt"
border-left-color="#000000" border-left-style="solid"
border-left-width="0.5pt" border-right-color="#000000"
border-right-style="solid" border-right-width="0.5pt"
border-top-color="#000000" border-top-style="solid"
border-top-width="0.5pt" padding-bottom="0mm"
padding-left="1.91mm" padding-right="1.91mm" padding-top="0mm">
<block xmlns="http://www.w3.org/1999/XSL/Format"
font-size="11.0pt" line-height="100%" space-after="0in">
<inline font-family="Calibri">{{ fruit.price }}</inline>
</block>
</fo:table-cell>
</fo:table-row>
{% endfor %}
</fo:table-body>
</fo:table>
<fo:block font-size="11.0pt" line-height="115%"
space-after="4mm">
<inline xmlns="http://www.w3.org/1999/XSL/Format"
font-size="8.0pt" />
</fo:block>
<fo:block font-size="11.0pt" line-height="115%"
space-after="4mm">
<inline xmlns="http://www.w3.org/1999/XSL/Format"
font-family="Calibri">Please remit funds to ABC Bank, account number 123 456
789. </inline>
<inline xmlns="http://www.w3.org/1999/XSL/Format"
font-size="8.0pt" />
</fo:block>
{% if condition1 %}
<fo:block font-size="11.0pt" line-height="115%"
space-after="4mm">
<inline xmlns="http://www.w3.org/1999/XSL/Format"
font-family="Calibri">This paragraph should be included.</inline>
</fo:block>
{% endif %}
</fo:flow>
</fo:page-sequence>
</fo:root>